Introduction
Imitation learning-based methods, such as π0 [1] and RDT-1B [2], show great promise for various manipulation tasks. However, training these end-to-end models requires substantial trajectory data, which presents a significant challenge for these approaches. To acquire robot execution trajectories, researchers and engineers usually build a teleoperation system, e.g., the ALOHA [3], to collect data from real scenarios. However, the scaling laws also constrain the model’s generalization capability, which depends on the training data’s scale and diversity. The realistic limitations, such as limited physical sites or cost considerations, make it difficult to attain such required data magnitude. One remedy for this problem is to collect data via simulation. NVIDIA has also officially provided a motion generation pipeline for robotic learning. Its link is
This post provides practical suggestions for building a data production pipeline using NVIDIAIsaac Sim. These suggestions include four aspects:
- The alignment of real and virtual control systems;
- Scene randomization;
- Choices of teleoperation methods;
- A recommended portion for mixed data with real and simulation.
The Alignment of Real and Virtual Control Systems
Building a robotic simulation system is as complex as building an actual robot since the simulation also requires core functions like forward/inverse kinematics, perception algorithms, closed-loop control, etc. Consequently, as shown in Figure 1, maintaining a unified communication interface between simulated and physical systems is critical. The upper-level decision/control frameworks can remain the same and compatible, reducing redundant system development and sim-to-real issues.
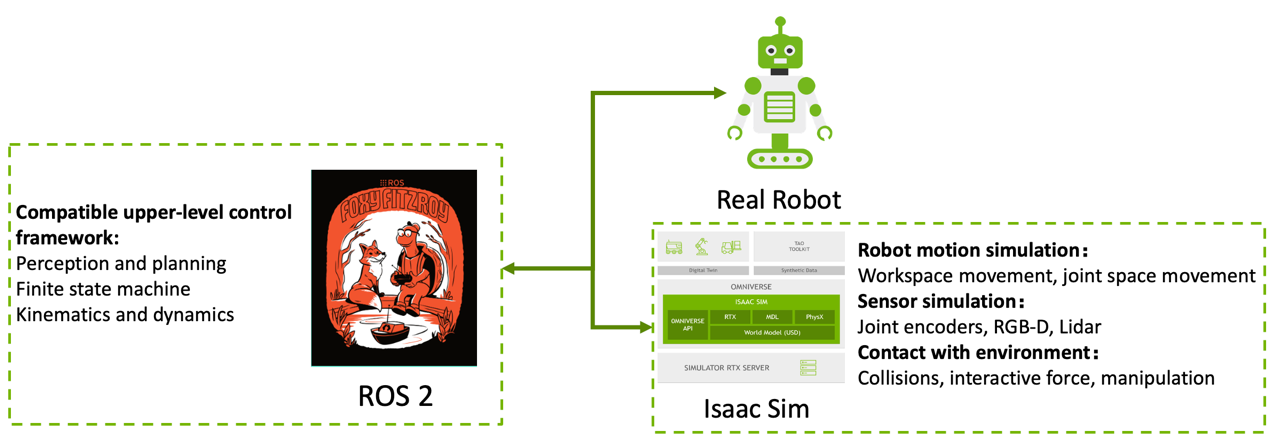
Figure 1: The communication interface between simulated and physical systems.
Frequency
For the control architecture, it is also important to consider the servo/simple/infer rate in each loop. Figure 2 shows two typical examples of control architecture. One is relatively straightforward in that the policy gives joint-angle commands, and we only need to interpolate the trajectories to 1000 Hz since the low-level control servo-rate is usually this much. The situation is more complex for the workspace commands because different modules run at different frequencies. Hence, in simulation, we must mimic these servo rates by properly setting physics_dt and rendering_dt and using the physical_callback_functions and render_callback_functions. In our practice, we set physics_dt to be the same as our low level controller servo-rate, since we believe this benefits the accuracy of temporal discretization and discrete dynamical computations.
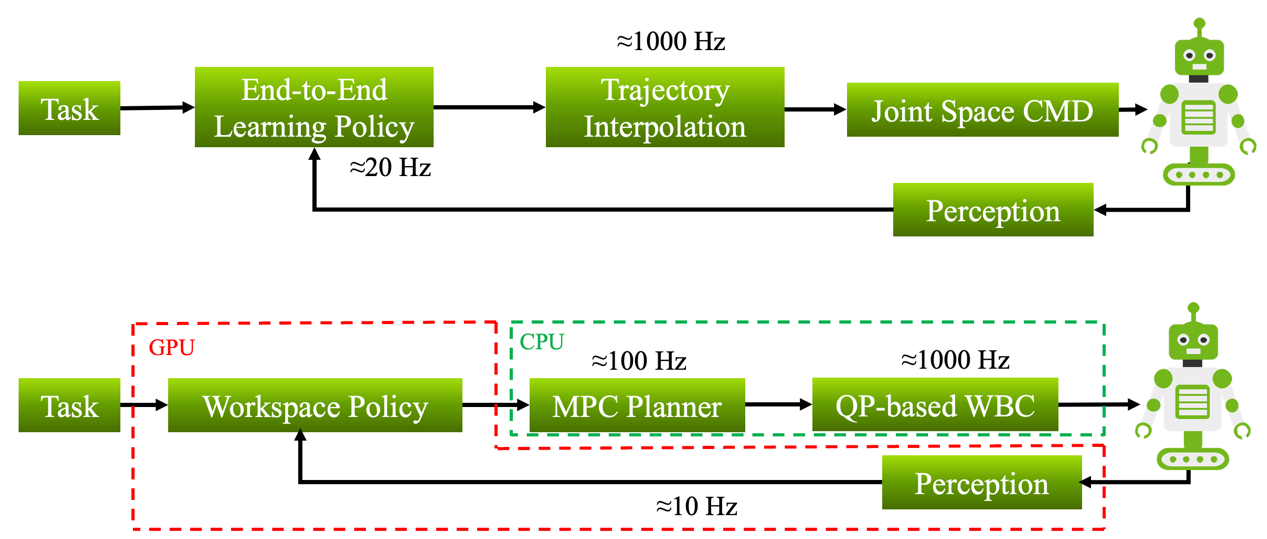
Figure 2: An example of control architecture.
The below pseudo-code shows the general settings concerning the servo-rate, and how we deal with different servo-rates.

Cameras
We mainly focus on the camera extrinsic and intrinsic matrices for the alignment of real and simulated cameras. Regarding the camera extrinsic matrices, attention has to be paid to the coordinate systems. Isaac Sim officially explained the Universal Scene Description (OpenUSD) and ROS frames, but beginners can still easily mess them up. Actually, the real camera and intrinsic matrix are determined under the ROS frame. Our trick for this issue is to create an extra XFormPrim, which gives the ROS camera frame +Y up and +Z forward, noted aswTx.Then, we attach the camera to this frame, and obviously, the viewport will point in an undesired direction. So we set the relative transformation between the XFormPrim and the USD camera frame, to correct the direction. Then, when we need to retrieve the camera extrinsic, we only need to query the pose ofwTx.
For the camera intrinsics, we need to set the aspect ratio, focal length, horizontal aperture, and vertical aperture. We can obtain the focal length from the camera’s user manual. Figure 3 shows an example of RealSense 450. Then, we can compute the required parameters via the code below.
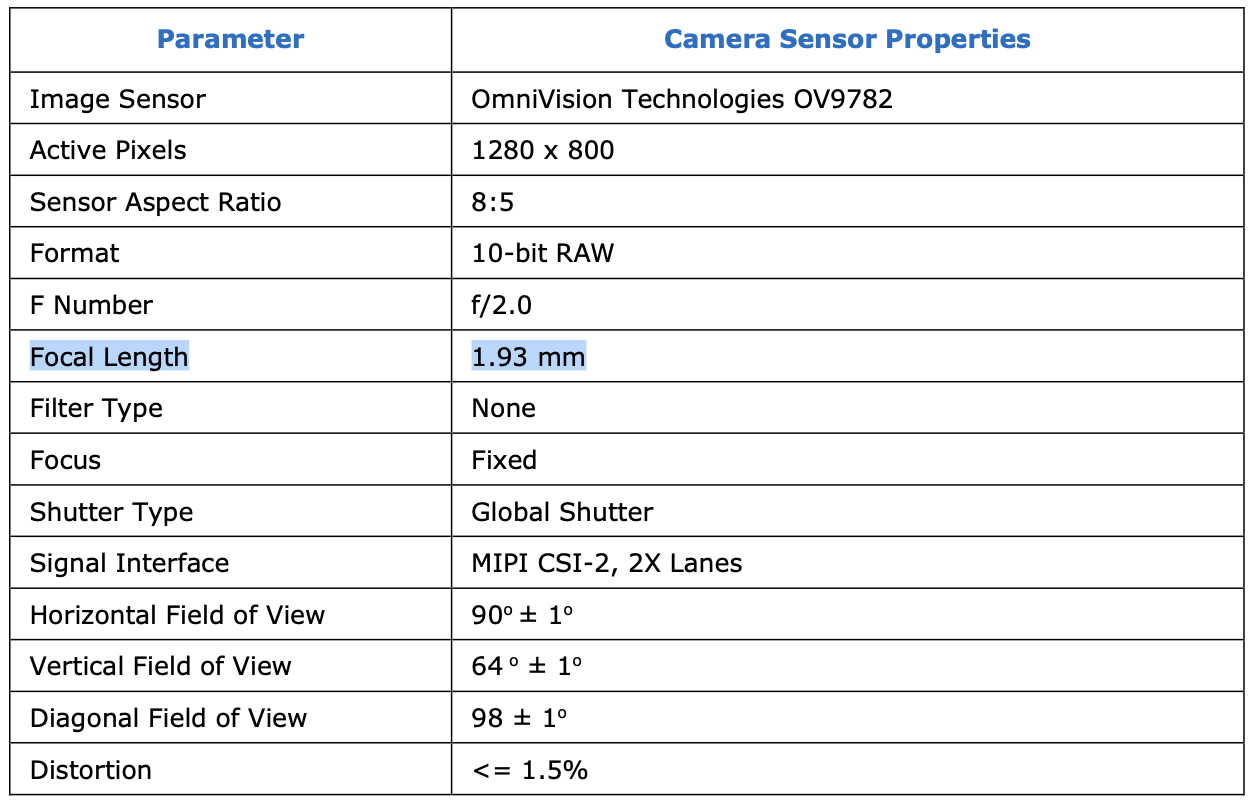
Figure 3: An example of RealSense 450.

Actuators
The Isaac Sim Proportional-Derivative (PD) controller for the actuators is of the form,
![]()

But the real robots have diverse control strategies including feedforward and feedback control. A common practice is to use neural networks [4] to formulate the behavior of actuators. We also provide another approach, which is system identification. It can fit a pair of parameters to obtain a similar behavior. Generally, there are two requirements for the excitation signal for identification: Firstly, the desired mode of the identified system must be persistently excited throughout the observation period. Secondly, optimal input conditions must be achieved based on features such as amplitude and bandwidth of the input signal. We have chosen the M-sequence as the signal since it exhibits properties closely resembling white noise, characterized by a constant power spectral density across all frequency bands.
Domain Randomization
Before deploying algorithms in the real world, domain randomization can significantly enhance a model’s robustness. Domain randomization relies on two key factors: a rich collection of digital assets and coordinate system post-processing. The former provides the generalization capability needed for domain randomization, and the latter prevents issues like coordinate errors or object clipping.
Considering that current robotic algorithms mainly focus on grasping tasks, we use this application scenario as an example. Below, we outline some digital assets and their corresponding coordinate system representations.

Figure 4: Example 3D assets in our database.

Figure 5: The coordinate system representation of the assets, for the ease of positioning and rotating objects in the simulation environment

Figure 6: Background visual material randomization.

Figure 7: Object pose randomization.

Figure 8: Dynamic environment randomization.
Comparative Analysis of Teleoperation Paradigms
Modern embodied AI systems increasingly rely on teleoperation-powered imitation learning to acquire physical manipulation skills. Three dominant approaches emerge in current practice:
Motion Capture Suits
Motion capture suits represent the gold standard for human motion digitization, operating through two primary technical pathway: inertial sensor networks and multi-camera optical systems. Inertial sensors, mainly based on IMUs (Inertial measurement units), capture data at 100-240Hz, while optical systems tracked by synchronized IR camera rigs reach 360Hz sampling. In controlled lab environments, optical variants achieve sub-millimeter precision (<0.1mm RMS error post-calibration) through photogrammetric triangulation. Operators wear sensor-embedded suits and perform calibration routines (T-pose/walking cycles) to establish biomechanical constraints, enabling real-time 3D skeletal reconstruction. While indispensable for training humanoid robots in dexterous manipulation, these systems demand: (1) 10-30min setup time for optical calibration. (2) A 20+k USD hardware investment. (3) Continuous marker maintenance.

Figure 9: Motion capture
VR Teleoperation
VR teleoperation systems have evolved from early exoskeleton-based interfaces to modern consumer-grade solutions leveraging inside-out tracking and deep learning, with contemporary approaches combining 6DoF controller input (1~10mm positional accuracy) and computer vision hand tracking to achieve 50-100Hz operational bandwidth. While cost-effective (<$1k per station) and scalable due to SteamVR/OpenXR standardization, these systems face inherent challenges: optical hand tracking exhibits 3-5mm jitter under variable lighting, and the absence of force feedback limits delicate operations like connector insertion. Recent advances in neural latent spaces and physics-aware retargeting demonstrate promising paths to bridge the sim2real gap, enabling transfer of VR-trained policies to real robots with <1cm spatial deviation in pick-and-place tasks.

Figure 10: VR teleoperation
Homomorphic Teleoperation
Homomorphic teleoperation systems establish dynamic isomorphism through master-slave robotic pairs, achieving millisecond-level synchronization and sub-Newton force rendering fidelity. Unlike vision-based methods, these systems preserve full state correspondence - joint angles, velocities, and wrench vectors are bidirectionally mapped through dynamic impedance matching algorithms, enabling micro-scale operations like PCB soldering and tissue-preserving surgical suturing. While requiring specialized operator training (50-100hrs proficiency timeline) and substantial capital investment, their mechanical transparency (<0.5dB wave distortion) and time-delay robustness make them indispensable for safety-critical applications. By unifying robotic manipulation across physical and simulated embodiments, homomorphic systems bridge the reality-virtuality gap in AI-driven automation, supporting adaptive control strategies that dynamically adjust to both physical and virtual constraints.

Figure 11: Homomorphic teleoperation
Metric | MoCap Suit | VR | Homomorphic Arm |
Spatial | 0.1~0.5 mm | 1~10 mm | 0.1~1 mm |
Setup Cost | $$$$ | $$ | $ |
Latency | 20~50 ms | 50~100 ms | <5 ms |
Skill Transfer Fidelity | Full-body | Upper-body | Full-body |
Data Richness | Bio-mechanical | Spatial-Temporal | Force Position |
From high-fidelity motion capture suits to vision-augmented hybrid interfaces, contemporary teleoperation systems collectively address diverse embodied intelligence needs: inertial-optical systems enable biomechanically-accurate humanoid training, VR frameworks democratize large-scale manipulation datasets, homomorphic architectures power micron-precision industrial automation, while neural-symbolic hybrids unlock cross-embodiment skill transfer. Yet across all paradigms, fundamental bottlenecks persist—even the most advanced systems generate <0.1% of the state-action space required for robust policy generalization, constrained by physical data capture rates (typically 50-200 demonstrations/day) and the exponential complexity of real-world contact dynamics. This data scarcity transcends modality superiority; whether capturing submillimeter surgical gestures or harvesting thousand-hour VR demonstrations, the curse of embodiment diversity (varying morphologies, material properties, environmental perturbations) demands systematic data augmentation. By integrating teleoperation’s ground-truth trajectories with synthetic variations—kinematic retargeting across robot morphologies, neural material synthesis via generative physics models, and photorealistic domain randomization through RTX-accelerated rendering—we construct combinatorial state spaces that obey real-world physics while exponentially expanding edge case coverage. The future of embodied AI lies not in choosing teleoperation modalities, but in orchestrating their fused realities through AI-enhanced data ecosystems where every human demonstration seeds a million synthetic evolutions.
Mixed Data
Digital Twin Environment Development
1. We developed a high-fidelity digital twin environment using NVIDIA Isaac Sim simulator to replicate real-world robotic tasks and assets. This approach enabled cost-effective training data collection and efficient evaluation of robotic behaviors. To maintain consistency with real-world datasets, we collected 30k trajectories through teleoperation in Isaac Sim. We implemented domain randomization techniques to enhance dataset diversity, varying parameters such as:
- Scene configurations
- Object varieties
- Surface textures and appearances
- Item placement positions
Co-training with Real and Simulation Data
1. To evaluate the effectiveness of simulation data in our RoboMIND [5], we conducted comprehensive experiments combining both real-world and simulation data.
2. Experimental Setup
- We focused on a challenging task called UprightBlueCup, which requires a Franka robotic arm to:
- Rotate approximately 90 degrees
- Insert its gripper horizontally into a cup’s opening
- Restore an overturned cup to its upright position
- We created a precise digital twin environment matching the real-world setup, including:
- Franka robotic arm configuration
- Table surface properties
- Target objects
- Camera positions and parameters

Figure 12: Real and simulation alignment
- Our dataset comprised:
- 100 real-world trajectories
- 500 simulation trajectories
- We evaluated the ACT [3] method using various real-world and simulation data ratios:
- Real-world data only
- Simulation data only
- Mixed ratios: 100:100, 100:200, 100:300, 100:400, and 100:500
Notably, we implemented direct data combinations without any sim2real transfer techniques.
Results and Analysis
- The figure shows the success rates of ACT in both real-world and simulation environments under different experimental settings.
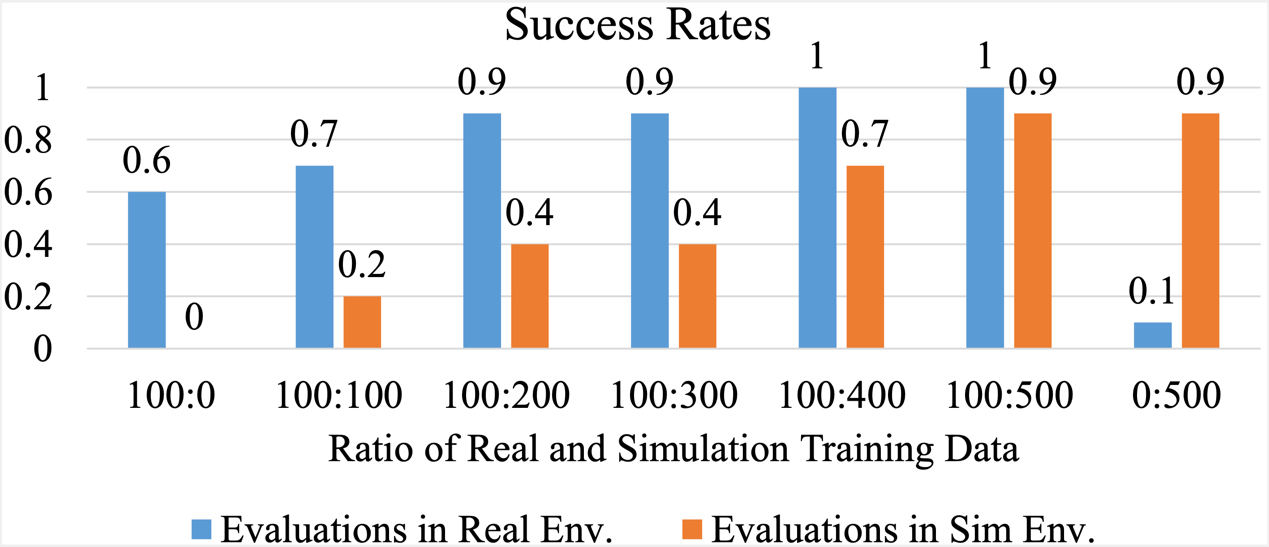
Figure 13 Experimental Results.
- Our experiments revealed several key findings:
- Simulation Data Impact: Increasing the proportion of simulation data improved success rates in both real-world and simulated environments, validating our high-fidelity simulation approach.
- Real-world Data Importance:
- Using only real-world data (100 trajectories): 60% success rate
- Using only simulation data (500 trajectories): 90% success rate in simulation but only 10% in real-world
- Hybrid approach (100 real + 500 sim): Up to 100% real-world success rate
- Diminishing Returns: We observed diminishing marginal returns as simulation data volume increased beyond certain thresholds.
- Failure Analysis: The primary failure mode when using simulation-only training was insufficient gripper closure during rotation, causing object slippage. This highlights the existing gap between simulated and real-world physics, particularly in contact-rich tasks.
These results demonstrate that while high-quality simulation data can significantly enhance robotic learning, a hybrid approach combining real-world and simulation data yields optimal performance. The findings also underscore the challenges in physics simulation fidelity for complex manipulation tasks.
# References
[1] BLACK, Kevin, et al. $pi_0 $: A Vision-Language-Action Flow Model for General Robot Control. arXiv preprint arXiv:2410.24164, 2024.
[2] LIU, Songming, et al. Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864, 2024.
[3] ZHAO, Tony Z., et al. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023.
[4] HWANGBO, Jemin, et al. Learning agile and dynamic motor skills for legged robots. Science Robotics, 2019, 4.26: eaau5872.
[5] RoboMIND:Wu K, Hou C, Liu J, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation[J]. arXiv preprint arXiv:2412.13877, 2024.